
企探-數據采集
- 發布時(shí)間(jiān):2021-10-25
企探-數據采集
【概要描述】企探--精準爬取網站的(de)網絡數據采集系統
- 發布時(shí)間(jiān):2021-10-25 12:03
企探--精準爬取網站的(de)網絡數據采集系統
利用網絡大數據面臨的(de)挑戰
互聯網上(shàng)有(yǒu)浩瀚的(de)數據資源,要想抓取這(zhè)些數據就離不開(kāi)爬蟲。鑒于網上(shàng)免費(fèi)開(kāi)源的(de)爬蟲框架多如牛毛,很(hěn)多人(rén)認為(wèi)爬蟲定是非常簡單的(de)事(shì)情。但(dàn)是如果你(nǐ)要定期、上(shàng)規模地(dì)準确抓取各種大型網站的(de)數據卻是一項艱巨的(de)挑戰。流行的(de)爬蟲框架Scrapy開(kāi)發者Scrapinghub在抓取了一千億個(gè)網頁後,總結了他(tā)們在爬蟲是遇到的(de)挑戰:
● 速度和(hé)數據質量:由于時(shí)間(jiān)通(tōng)常是限制因素,規模抓取要求你(nǐ)的(de)爬蟲要以很(hěn)高(gāo)的(de)速度抓取網頁但(dàn)又(yòu)不能拖累數據質量。對(duì)速度的(de)這(zhè)張要求使得爬取大規模産品數據變得極具挑戰性。
● 網站格式多變:網頁本身(shēn)是基于HTML這(zhè)種松散的(de)規範來(lái)建立的(de),各網頁互相(xiàng)不兼容,導緻網頁結構複雜(zá)多變。在規模爬取的(de)時(shí)候,你(nǐ)不僅要浏覽成百上(shàng)千個(gè)有(yǒu)着草率代碼的(de)網站,還(hái)将被迫應對(duì)不斷變化(huà)的(de)網站。
● 網絡訪問(wèn)不穩定:如果網站在一個(gè)時(shí)間(jiān)訪問(wèn)壓力過大,或者服務器(qì)出現(xiàn)問(wèn)題,就可能不會正常響應用戶查看(kàn)網頁的(de)需求。對(duì)于網頁數據采集工(gōng)具而言,一旦出現(xiàn)意外(wài)情況,很(hěn)有(yǒu)可能因為(wèi)不知道(dào)如何處理(lǐ)而崩潰或者邏輯中斷。
● 網頁內(nèi)容良莠不齊:網頁上(shàng)顯示的(de)內(nèi)容,除了有(yǒu)用數據外(wài),還(hái)有(yǒu)各種無效信息;有(yǒu)效信息也通(tōng)過各種顯示方式呈現(xiàn),網頁上(shàng)出現(xiàn)的(de)數據格式多樣。
● 網頁訪問(wèn)限制:網頁存在訪問(wèn)頻(pín)率限制,網站訪問(wèn)頻(pín)率太高(gāo)将會面臨被封鎖IP的(de)風(fēng)險。
● 網頁反扒機(jī)制:有(yǒu)些網站為(wèi)了屏蔽某些惡意采集而采取了防采集措施。比如Amazon這(zhè)種較大型的(de)電(diàn)子(zǐ)商務網站,會采用非常複雜(zá)的(de)反機(jī)器(qì)人(rén)對(duì)策使得析取數據困難許多。
● 數據分析難度高(gāo):規模化(huà)的(de)數據采集會導緻數據質量得不到保證,變髒或者不完整的(de)數據很(hěn)容易就會流入到你(nǐ)的(de)數據流裏面,進而破壞了數據分析的(de)效果。
為(wèi)了充分利用網絡大數據,企業(yè)需要一個(gè)有(yǒu)效的(de)系統,該系統不僅可以自(zì)動化(huà)從(cóng)網頁中提取數據,同時(shí)對(duì)數據進行篩選、清理(lǐ)和(hé)标準化(huà),并将這(zhè)些數據集成到現(xiàn)有(yǒu)工(gōng)具鏈和(hé)工(gōng)作(zuò)流中。
企探網絡數據采集系統是一款可以精準爬取網站的(de)爬蟲工(gōng)具,采用愛智慧科(kē)技(jì)自(zì)主研發的(de)TMF框架為(wèi)架構主體(tǐ),支持開(kāi)發可操作(zuò)的(de)網絡數據采集系統。

企探對(duì)以上(shàng)挑戰的(de)解決辦法
24小(xiǎo)時(shí)自(zì)動化(huà)爬蟲采集,制定清晰采集字段,保證初步采集速度和(hé)質量;
● 兼顧計(jì)算(suàn)機(jī)和(hé)人(rén)處理(lǐ)網頁數據的(de)特征,能夠應對(duì)網頁結構的(de)複雜(zá)多變;
● 雲服務器(qì)協同合作(zuò),達到采集素的(de)的(de)平衡點,在不降低(dī)采集速度的(de)同時(shí)保證不被封鎖IP
● 內(nèi)置邏輯判斷方案,自(zì)定義網站訪問(wèn)不穩定時(shí)的(de)智能應對(duì)機(jī)制;
● 對(duì)采集的(de)原始數據進行“清洗、歸類、注釋、關聯、映射”,将分散、零亂、标準不統一的(de)數據整合到一起,提高(gāo)數據的(de)質量,為(wèi)後期數據分析奠定基礎。
● 企探的(de)數據采集屬于正常的(de)采集行為(wèi),倡導在獲得網站授權采集後進行采集,共同維護互聯網規範。
企探網絡數據采集方案
企探網絡數據采集系統實現(xiàn)數據從(cóng)采集,處理(lǐ)到應用的(de)全生(shēng)命周期管理(lǐ),達到網絡爬蟲 ,另類數據 ,網頁解析及采集自(zì)動化(huà)。目前企探已建設自(zì)己的(de)企業(yè)庫數據 (3000+企業(yè)數據信息),律師(shī)數據庫 (全過30w+律師(shī)數據信息)且這(zhè)些信息都(dōu)是通(tōng)過數據處理(lǐ)與分析,用戶可直接使用于商務中!
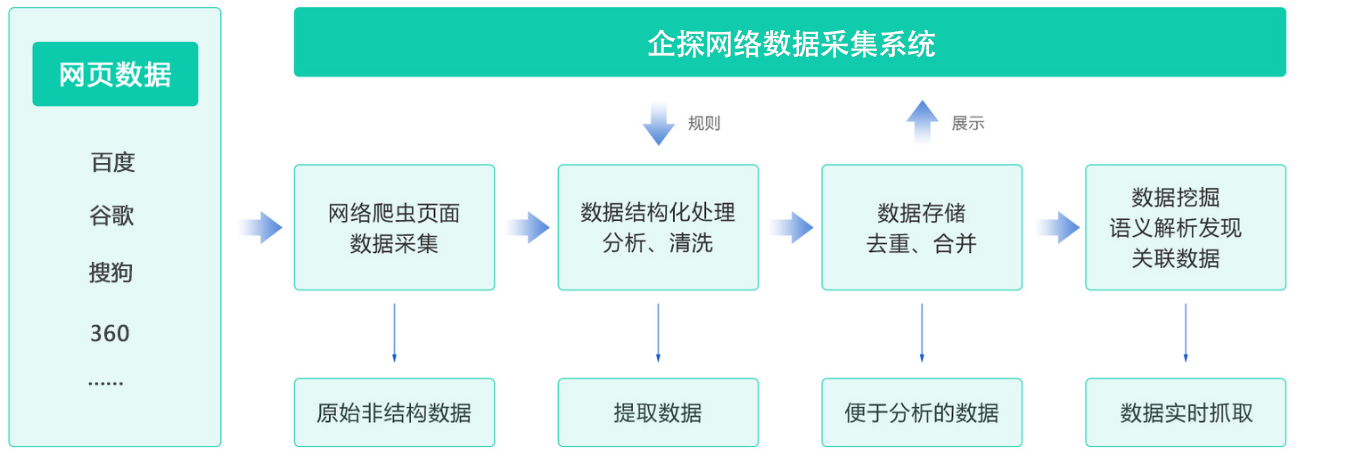
數據提取
企探通(tōng)過網絡爬蟲、結構化(huà)數據、本地(dì)數據、物(wù)聯網設備、人(rén)工(gōng)錄入等進行全方位實時(shí)的(de)彙總采集。對(duì)各種來(lái)源(如RFID射頻(pín)數據 、傳感器(qì)數據、移動互聯網數據、社交網絡數據等)的(de)非結構化(huà)數據進行全自(zì)動化(huà)采集,借助網絡爬蟲或網站API,從(cóng)網頁獲取非結構化(huà)數據數據,将其統一結構化(huà)為(wèi)本地(dì)數據。
數據管理(lǐ)
企探網絡數據采集系統合并來(lái)自(zì)多個(gè)來(lái)源的(de)數據,構建複雜(zá)的(de)連接和(hé)聚合。針對(duì)非結構化(huà)、半結構化(huà)數據的(de)特殊性,在爬取完數據後還(hái)需要對(duì)采集的(de)原始數據進行“清洗、歸類、注釋、關聯、映射”等一系列操作(zuò)後,将分散、零亂、标準不統一的(de)數據整合到一起,提高(gāo)數據的(de)質量,為(wèi)後期數據分析奠定基礎。
數據儲存
企探網絡數據采集系統在獲得所需的(de)數據并将其分解為(wèi)有(yǒu)用的(de)組件(jiàn)之後,通(tōng)過可擴展的(de)方法來(lái)将所有(yǒu)提取和(hé)解析的(de)數據存儲在數據庫或集群中,然後創建一個(gè)允許用戶可及時(shí)查找相(xiàng)關數據集或提取的(de)功能。
解決方案優勢
通(tōng)過采用企探網絡數據采集解決方案,實現(xiàn)了以下(xià)幾個(gè)優勢:
● 全面的(de)數據服務 -通(tōng)過企探網絡數據采集系統,您可以輕松地(dì)獲得網絡數據。您可以實現(xiàn)自(zì)動化(huà)提取、更新、轉換數據并确保不同的(de)數據元素符合常見的(de)數據格式。
● 最新數據- 解決方案的(de)自(zì)動化(huà)意味着您的(de)組織可以以最少的(de)工(gōng)作(zuò)量進行持續提取。因此,組織可以确保始終使用最新的(de)數據。
● 準确的(de)數據- 企探網絡數據采集系統使團隊不僅能夠消除與手動提取和(hé)轉換相(xiàng)關的(de)工(gōng)作(zuò),而且還(hái)能消除與人(rén)工(gōng)工(gōng)作(zuò)相(xiàng)關的(de)潛在錯(cuò)誤。
● 降低(dī)成本-企業(yè)自(zì)身(shēn)無需昂貴的(de)工(gōng)程團隊不斷編寫代碼,監控質量和(hé)維護邏輯,就能夠規模快速,經濟高(gāo)效地(dì)獲得高(gāo)質量的(de)網絡數據。
● 可擴展性- 企探網絡數據采集系統支持提取數百萬個(gè)數據點和(hé)Web查詢。
總結
企探科(kē)技(jì)自(zì)主研發的(de)網絡數據采集系統是集Web數據采集,分析和(hé)可視(shì)化(huà)為(wèi)一體(tǐ)的(de)數據集成系統,确保您從(cóng)Web數據中獲得最大的(de)洞察力和(hé)價值。
7*24小(xiǎo)時(shí)服務熱線
0755-28248002
地(dì)址:深圳市(shì)龍崗區(qū)荷坳龍崗大道(dào)7240,7242号衆點青創中心三樓
電(diàn)子(zǐ)郵件(jiàn):azh@aitech.xin
版權所有(yǒu) © 2020 深圳市智聯智慧科技有限公司 京ICP證000000号